


GPUs are no longer the future of AI hardware. By 2026, their limitations in cost, energy efficiency, and scalability have become insurmountable. As AI workloads grow exponentially, the industry is shifting to specialised silicon like ASICs, TPUs, neuromorphic chips, and quantum processors. These technologies offer faster performance, lower energy use, and tailored solutions for specific AI tasks.
Key Takeaways:
- GPUs hit limits: Rising costs, inefficiencies, and power demands make them unsuited for modern AI.
- ASICs & TPUs: Focused on specific tasks, delivering better performance-per-watt but less flexible.
- Neuromorphic chips: Mimic the brain, achieving high efficiency for edge AI and low-power applications.
- Quantum processors: Handle complex problems with exponential scaling, despite current challenges.
- Energy demand: AI now consumes 1–2% of global electricity, driving the need for efficient silicon.
The future lies in combining these technologies for smarter, more efficient AI systems. This shift is reshaping hardware strategies across industries.
Post-GPU AI Hardware Comparison: ASICs, TPUs, Neuromorphic and Quantum Processors
The End of GPU Scaling? Compute & The Agent Era - Tim Dettmers (Ai2) & Dan Fu (Together AI)
sbb-itb-e314c3b
Custom Silicon for AI: ASICs and TPUs
Custom silicon is reshaping AI performance by addressing computational challenges that GPUs can't fully tackle. The focus has shifted towards two main types of custom silicon: application-specific integrated circuits (ASICs) and tensor processing units (TPUs). While both are tailored for AI tasks, they come with distinct functionalities and advantages.
ASICs: Focused Chips for Specific AI Tasks
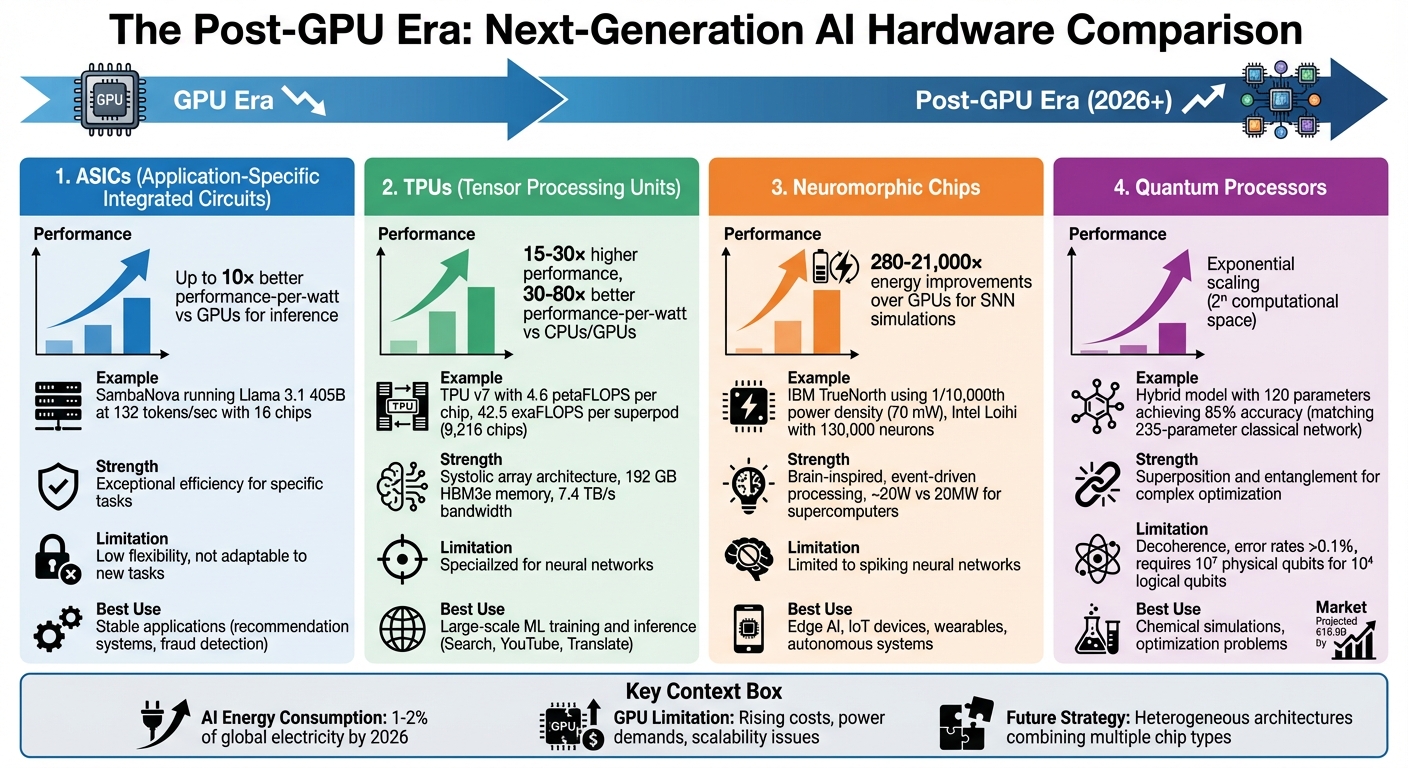
ASICs are designed to handle one specific task with exceptional efficiency, often delivering up to 10× better performance-per-watt compared to GPUs for inference tasks [4].
For instance, in 2025, SambaNova showcased the power of ASICs by running the Llama 3.1 405B model at 132 tokens per second and the DeepSeek-R1 671B model at 198 tokens per second, using just 16 chips [1]. However, this level of efficiency comes at a cost: flexibility. ASICs are not easily adaptable to new tasks or changes in model architectures. As Semiconductor Engineering noted:
"Fixed-function accelerators embedded in silicon only stay useful if models don't adopt new operators" [6].
This makes ASICs ideal for stable, high-volume applications like recommendation systems or fraud detection, where algorithms remain relatively unchanged.
Broadcom has also played a significant role in this space, partnering with Google to co-develop TPUs and providing proprietary high-speed interfaces through TSMC [5].
While ASICs thrive in fixed operations, TPUs push the boundaries by scaling neural network computations for more dynamic AI requirements.
Google TPUs: Scaling Machine Learning Efficiency
TPUs, a specialised type of ASIC, are engineered specifically for neural network operations. Google introduced TPUs to overcome the limitations of traditional processors when handling the vast matrix multiplications critical to deep learning.
The key innovation behind TPUs lies in their systolic array architecture, which streams data efficiently across multiply-accumulate units to minimise memory bottlenecks. Norman P. Jouppi, VP and Engineering Fellow at Google, highlighted their impact:
"The TPU achieved 15–30× higher performance and 30–80× higher performance-per-watt than contemporary CPUs and GPUs" [5].
The latest TPU v7 (Ironwood) exemplifies this leap in performance, offering 4.6 petaFLOPS of FP8 compute per chip, slightly surpassing Nvidia's B200 at 4.5 petaFLOPS [3]. A TPU v7 superpod, consisting of 9,216 chips, scales up to deliver an astounding 42.5 exaFLOPS of FP8 compute [3]. Each chip is equipped with 192 GB of HBM3e memory and a bandwidth of 7.4 TB/s, enabling support for context windows with millions of tokens [3].
In December 2025, Anthropic committed to deploying over one million TPU v7 chips, providing more than a gigawatt of computational capacity to train and serve its future Claude models [3][8]. Google also relies heavily on TPUs for tasks like Search ranking, YouTube recommendations for billions of users, and Google Translate, which processes over a billion requests daily [3][7].
Modern TPUs include SparseCores, specialised processors that enhance embedding-intensive tasks - like recommendation systems - by 5–7× compared to general matrix units [3]. This makes them especially effective for large language models with vast vocabularies, further solidifying their role in advancing AI capabilities.
Neuromorphic Chips: Brain-Inspired Computing
Neuromorphic chips stand out from traditional processors like ASICs and TPUs by mimicking the structure of the human brain. Using artificial neurons and synapses, these chips handle computations with remarkable energy efficiency - operating on around 20 W, compared to supercomputers that can consume up to 20 MW [10].
What sets them apart is their processing method. Unlike conventional chips that run continuously, neuromorphic systems activate only during specific "spikes." This approach avoids the von Neumann bottleneck, a limitation in traditional architectures where data transfer between memory and processing units slows performance [10].
A great example of this efficiency is IBM's TrueNorth chip. It uses just 1/10,000th the power density of standard processors. With 4,096 cores and 1 million programmable neurons, it handles tasks like image classification while consuming only 70 mW [10]. As Chris Eliasmith, a professor at the University of Waterloo, points out:
"Neuromorphic chips introduce a level of parallelism that doesn't exist in today's hardware, including GPUs and most AI accelerators" [10].
How Neuromorphic Chips Work
Neuromorphic processors rely on Spiking Neural Networks (SNNs), which process data as temporal spike patterns instead of the dense mathematical layers used in traditional deep learning [10]. These systems function asynchronously, meaning different parts of the chip can work independently without a central clock. This design reduces latency and energy use [10].
In August 2025, researchers at Zhejiang University unveiled DarwinWafer, a wafer-scale system combining 64 Darwin3 chiplets. It achieved 64 TSOPS with an energy efficiency of 4.9 picojoules per synaptic operation, enabling simulations of entire zebrafish and mouse brains [12].
Intel's Loihi chip, introduced in 2017, features 128 neuromorphic cores and 130,000 artificial neurons. By 2020, Intel scaled this up with the Pohoiki Beach system, integrating 64 Loihi chips to simulate 8 million neurons. This system has been used for tasks like odour recognition and sensory processing [9][10]. Abu Sebastian from IBM Zurich explains the advantage:
"The spikes begin to propagate immediately to higher layers once the lower layer provides sufficient activity. This is very different from conventional deep learning, where all layers have to be fully evaluated before the final output is obtained" [10].
This efficient processing design is particularly well-suited for low-power, real-world applications.
Applications in Low-Power AI
The energy-efficient nature of neuromorphic chips makes them perfect for edge AI applications. For certain SNN simulations, they offer 280–21,000× energy improvements over GPUs [13]. As a result, they are ideal for IoT devices, wearables, and autonomous systems.
One notable example is the SpiNNaker2 system, developed at Technische Universität Dresden. In 2023, it achieved 96.6% accuracy on MNIST digit recognition while using just 1.3% synaptic connectivity and consuming a fraction of the energy required by an Intel i5-6500 CPU. This system is now being expanded into a 5-million core "brain-like supercomputer" for real-time radar gesture recognition and event-based processing [11].
Commercial applications are also emerging. SynSense's Speck and Xylo processors enable "always-on" vision and audio processing in consumer devices with milliwatt-level power consumption [13]. These chips power features like voice-wake commands, presence detection, and ambient audio analysis in smart home gadgets and wearables. Adam Stieg from UCLA highlights the potential:
"The ability to perform computation and learning on the device itself, combined with ultra-low energy consumption, could dramatically change the landscape of modern computing technology" [10].
Quantum Processors: Next-Generation AI Computing
Quantum processors mark a groundbreaking shift in how computers manage AI tasks. Unlike traditional chips that rely on binary bits, quantum processors use qubits, which can exist in multiple states simultaneously thanks to superposition. This allows for exponential scaling - an n-qubit system can encode information on an entirely different scale compared to classical systems. Richard Feynman captured this revolutionary idea perfectly when he said:
"Nature isn't classical dammit, and if you want to make a simulation of Nature you better make it quantum mechanical." - Richard Feynman [20]
The concept of "quantum-centric supercomputing" is emerging, blending Quantum Processing Units (QPUs) with classical high-performance computing to tackle challenges like chemical simulations and optimisation problems that traditional processors struggle to handle [15]. A striking example of this potential came in October 2019, when Google Quantum AI and NASA used a 53-qubit processor to perform a calculation that would have taken classical supercomputers thousands of years [22].
How Quantum Computing Works with AI
Quantum processors harness principles like superposition, entanglement, and interference to explore numerous solutions simultaneously, accessing a 2ⁿ-dimensional computational space. Entanglement, in particular, creates connections between qubits that classical bits simply cannot replicate.
When applied to AI, quantum processors shine in specialised algorithms like the Variational Quantum Eigensolver (VQE) and the Quantum Approximate Optimisation Algorithm (QAOA), which are designed to navigate complex optimisation problems efficiently [16] [17]. Hybrid systems combining quantum and classical computing have also shown impressive results. A 2025 study, for example, demonstrated that a hybrid model with 120 parameters achieved a classification accuracy of 85% ± 0.03, matching the performance of a fully classical network with 235 parameters. Furthermore, 95.9% of hybrid networks surpassed key accuracy thresholds during training, compared to 76.3% for classical networks [18].
The automotive sector is expected to benefit significantly, with quantum AI applications potentially valued between €2.8 billion and €4.7 billion by 2035. On a global scale, the quantum AI market is projected to grow to approximately €16.9 billion by 2030 [23]. In 2024, researchers introduced a quantum deep reinforcement learning method for autonomous vehicle navigation, achieving faster training and greater stability with fewer parameters than classical methods [23].
Much like ASICs and neuromorphic chips, quantum processors represent a leap forward in addressing the limitations of conventional AI hardware.
Current Limitations and Future Potential
Despite their promise, quantum processors still face significant challenges. One of the biggest obstacles is decoherence, where qubits lose their state [19]. Current two-qubit gate error rates often exceed 0.1%, and experiments have shown that cosmic rays can cause error bursts, limiting logical errors to around 10⁻¹⁰ [19] [20].
Another challenge is the I/O bottleneck. A theoretical 10,000-qubit error-corrected quantum computer would have an I/O bandwidth about 10,000 times smaller than today's classical chips [21]. As highlighted by Communications of the ACM:
"Quantum computers will be practical for 'big compute' problems on small data, not big data problems." - Communications of the ACM [21]
Scaling from current 100-qubit Noisy Intermediate-Scale Quantum (NISQ) devices to Fault-Tolerant Quantum Computing (FTQC) is a monumental task. It’s estimated that around 10⁷ physical qubits will be required to support 10⁴ logical qubits [19]. Additionally, current systems often demand up to two hours of daily recalibration, with the least efficient 10% of qubits performing 30–100 times worse than the median [19]. However, advances like NVQLink, which has achieved round-trip latencies between HPC and QPU controllers as low as 3.96 microseconds, are paving the way for real-time error correction [14].
To bridge the gap before full fault-tolerance is achieved, researchers are exploring "circuit knitting" techniques. These involve linking multiple QPUs with tightly integrated classical processors to achieve computational advantages even with current limitations [15] [19].
AI Strategy in the Post-GPU Era: Insights from RAISE Summit

RAISE Summit's Focus on Hardware Innovation
The RAISE Summit 2026, held on 8–9 July at the Carrousel du Louvre in Paris, is set to spotlight the evolving hardware landscape with its dedicated track, "The Silicon Horizon". This track delves into chip advancements, supply chain dynamics, and the challenges of the post-GPU era. Drawing over 9,000 attendees - more than 80% of whom are C-level executives and founders - the event fosters high-level discussions on reshaping hardware infrastructure strategies [24][26][27].
One of the summit's key frameworks, "Compute as Capital", encourages leaders to view hardware investments as strategic assets rather than routine operational costs [26][27]. Nick Horne, VP of ML Engineering at Arm, captures the essence of this shift:
"A 'brute force' approach (to AI) is economically unsustainable, so there will be demand for smarter, more power-efficient silicon solutions." [2]
The sessions also address the Energy-Compute Nexus, a critical issue as power limitations emerge as the primary barrier to AI scalability. With new accelerators reaching power demands of up to 1 kW per chip, the need for energy-efficient solutions has become more pressing [26][28]. Additionally, the MACHINA Summit, held on 7 July, explores how AI transitions from software to physical applications like autonomous systems, complementing the broader discussions at RAISE [27]. These topics aim to equip leaders with actionable strategies for navigating the rapidly changing hardware landscape.
What Leaders Can Learn at RAISE Summit
The RAISE Summit provides executives with valuable tools to assess post-GPU silicon, focusing on Total Cost of Ownership (TCO) rather than just performance benchmarks. For example, Google's TPU v7 (Ironwood) clusters reportedly achieve a 30% reduction in TCO compared to equivalent NVIDIA solutions in 2026. Meanwhile, specialised ASICs demonstrate up to 1,000× efficiency improvements in performance-per-watt for specific tasks [25].
Another key topic is Vertical Hypercomputing, which highlights the shift from general-purpose chips to silicon tailored for specific AI models and reasoning tasks. Google's Trillium (TPU v6) serves as a prime example of this trend [25]. Attendees also gain insights into asymmetric architectures, which combine older, energy-efficient chips for simpler tasks with advanced NPUs for complex reasoning. This approach balances cost and performance, offering a more sustainable path forward [25].
Networking opportunities at the summit, including discussions on sovereign infrastructure and secure cloud environments, are guided by the "4F Compass" framework: Foundation, Frontier, Friction, and Future. This tool helps leaders navigate hardware development and plan for technology transitions effectively [26][28]. Together, these insights illustrate how tailored hardware solutions are reshaping AI strategies in the post-GPU world.
Conclusion: What's Next for AI Hardware
The dominance of GPUs is fading. The rise of specialised architectures - like ASICs, neuromorphic chips such as Intel's Hala Point, and photonic processors from companies like Lightmatter - is reshaping the AI hardware landscape. For instance, Lightmatter's system demonstrated impressive efficiency in January 2025, running ResNet and BERT models at 65.5 trillion operations per second while consuming just 79.6 W of power[1]. These advancements highlight how diverse silicon designs are now surpassing traditional GPUs in both speed and energy efficiency.
This shift isn't just technical; it's economic. With AI predicted to account for 1–2% of global electricity usage by 2026[1], the focus has turned to energy-efficient solutions. Performance-per-watt has become the critical benchmark for sustainable AI development. Microsoft's 1.58-bit BitNet architecture exemplifies this trend, achieving 41× lower energy consumption compared to full-precision models[1]. The days of relying on energy-intensive, brute-force methods are giving way to smarter, power-conscious designs[2].
As these technologies evolve, organisations need to rethink their AI infrastructure. The future lies in heterogeneous architectures that blend GPUs for training, ASICs for inference, and neuromorphic chips for edge applications. This combination is emerging as the new standard[1]. The challenge now is how quickly businesses can adapt to specialised silicon solutions.
The RAISE Summit 2026 provides a platform for navigating this transition. With sessions like "The Silicon Horizon" and "Compute as Capital", attendees can explore frameworks for evaluating post-GPU technologies. These discussions focus on metrics like Total Cost of Ownership rather than just raw performance, offering practical strategies for staying ahead in the rapidly changing hardware landscape.
FAQs
When should I choose an ASIC or TPU instead of a GPU?
If you're tackling highly specific tasks like inference, ASICs are your go-to choice. They can deliver up to 70% lower power consumption while offering excellent efficiency for large-scale setups. On the other hand, TPUs shine when it comes to large-scale deep learning tasks, whether it's training or inference. They're built to handle matrix-heavy workloads with impressive throughput. Meanwhile, GPUs remain a versatile option, making them ideal for a wide range of AI tasks, especially when flexibility is a priority.
What AI workloads benefit from neuromorphic chips today?
Neuromorphic chips are a great match for low-power, always-on edge AI tasks. They shine in areas like sensory processing and real-time, energy-conscious computing, making them ideal for jobs such as speech and image recognition. Their design allows for impressive efficiency in situations where constant operation and quick reactions are essential.
What’s a realistic timeline for quantum processors to help with AI in production?
Quantum processors are anticipated to play a role in supporting AI in production environments between 2035 and 2040. This prediction assumes a growth trajectory comparable to Moore’s law. However, achieving practical applications will demand quantum systems with several million qubits. Reaching this milestone will heavily rely on advancements in quantum hardware and the ability to scale these systems effectively.




